Comment System
The current comment system (2023-02-24) was written from scratch by HPR volunteers. It replaced a proprietary (and rather unsatisfactory) system.
It has been in use since 2017, has proved reliable and has needed very little maintenance.
Overview
There are three main components of the system:
- A database table called
commentswhich holds each comment with its metadata. - PHP code which takes in each comment from the comment form (available on
every show page) and converts it to a JSON format which is available to
authorised people on the website and is emailed to the
adminlist and tocomments@hackerpublicradio.org. - The scripts stored in the
Comment_systemdirectory on the Gitea repo. These are capable of decoding the email or or taking the JSON files and offering them for approval. If approved the comment is added to the database, otherwise it is not added. The incoming file is stored for future access if needed. The scripts communicate the decision to the PHP code on the server and the intermediate files are cleaned up there.
Database
The comments table has the following structure:
+---------------------+----------+------+-----+---------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------------+----------+------+-----+---------------------+----------------+
| id | int(5) | NO | PRI | NULL | auto_increment |
| eps_id | int(5) | NO | MUL | NULL | |
| comment_timestamp | datetime | NO | | NULL | |
| comment_author_name | text | YES | | NULL | |
| comment_title | text | YES | | NULL | |
| comment_text | text | YES | | NULL | |
| last_changed | datetime | NO | | current_timestamp() | |
+---------------------+----------+------+-----+---------------------+----------------+
idis an incrementing primary keyeps_idis the primary key (show number) of theepstable to which the comment is linkedcomment_timestampcontains the time that the comment was submittedcomment_author_nameholds the name of the comment author as submitted (there are no checks against know hosts)comment_titleholds the title submitted by the comment authorcomment_textcontains the body of the commentlast_changedcontains the timestamp of the last change made to the comment (this is managed by a trigger calledbefore_comments_update)
Note It's possible to edit a comment in the database. There is a command-line tool under the Database directory which enables this, using Vim as the editor. It's not documented at the moment.
Server code
TBA
Local processing
The management of comments was designed to be a local command-line process using a Perl script. A connection with the HPR database is needed and this
is achieved using an SSH tunnel. The Pdmenu menu system is used used to streamline things, but that's just a personal preference (though the
.pdmenurc menu definition file can be made available if required).
Modes of working
There are two modes of working:
- An email is sent to
comments@hackerpublicradio.org(a limited distribution address list). The email contains a JSON attachment with the comment details. - A copy of the JSON attachment file is stored in the directory
~hpr/commentson the main server.
A single script called process_comments can handle the two modes. It expects two spool areas, one for email messages and the other for JSON files.
Email messages are written to the spool area (CommentDrop) by the Thunderbird MUA which has the ability to make message copies using a plugin. (More
details to follow.)
/home/cendjm/HPR/CommentDrop/
├── banned
├── processed
└── rejected
The sub-directories are where process_comments places the messages after processing (explained later).
JSON files are copied from the comments directory on the server into the JSON spool area (imaginatively) called json:
json
├── banned
├── processed
└── rejected
The sub-directories are used for the same purpose as in CommentDrop (explained later).
The JSON mode is only used when there are mail problems. The files are collected using Pdmenu which uses scp to achieve this.
NOTE These spool directory locations are "baked into" the process_comments script and should be in a configuration file.
The process_comments script
This a Perl script which contains internal documentation (in POD format). Information about how to run the script can be obtained with the -help
option, or the full documentation can be viewed with the option -doc. A copy of the internal documentation is available in manual page format by
following this documentation link.
TBA
NOTE The script documentation is in need of updates.
Screenshots
-
Image 1:
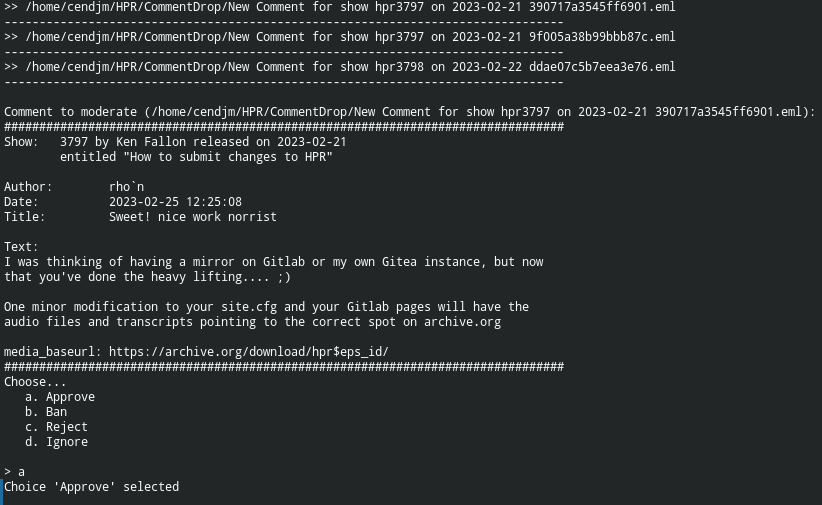
- Running
process_commentswith three comments in the mail spool area. This example uses the-verboseoption so a report of what messages have been found is produced. The files have strange names generated from the mail subject, courtesy of the Thunderbird plugin. - The first comment is offered for approval using a template to display the contents of the JSON attachment
- The options are
approve,ban,rejectandignore. In this case choiceais selected to approve this comment.
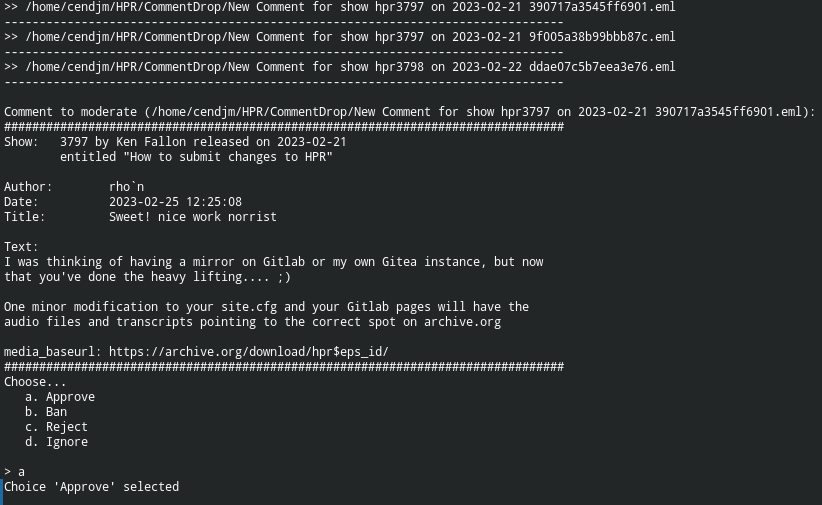
- Running
-
Image 2:
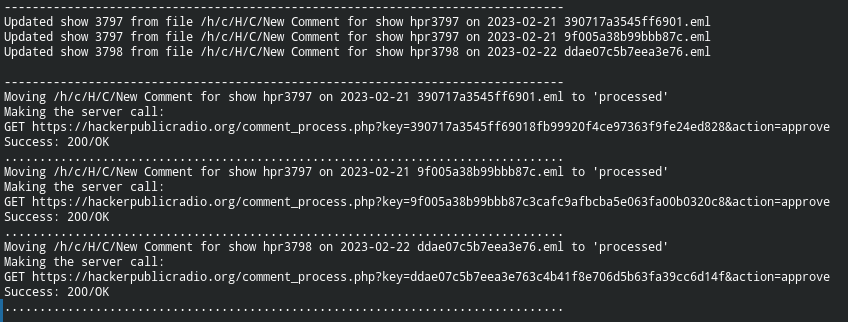
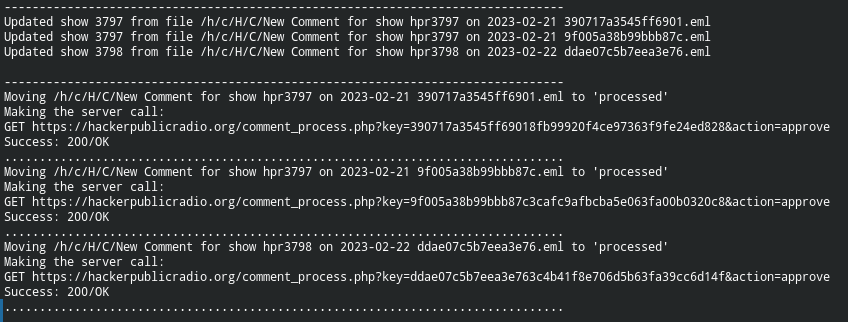
- All three comments have been processed, with each one being approved. The script actions the choices at the end.
- The (
-verbose) output lists the comments being added to the database (attached to the relevant shows). - Each mail message is moved to the
processedsub-directory. - The script communicates with the server requesting the deletion of the original JSON files, and the success return (
200/OK) shows that this has been completed.
Back to Home page