How To Do Stuff
This is the TLDR part of the documentation
Upload future shows to the IA
This task uses future_upload. It is best run in the morning in the UK/Europe
time zones since the IA servers are based on the west coast of the USA and it
will be the early hours of the morning there.
Sometimes the servers can be overloaded and attempts to upload will be met
with error messages and the uploader will retry. It is possible to check
whether an overload is likely by running the ia command, and this will be
added later.
Run the command:
./future_upload -d0
A lot of output will be generated because make_metadata is run in verbose
mode, and the ia command run to perform the uploads is naturally quite
verbose.
This script is documented elsewhere, but in brief, it does the following:
- Looks for all audio files in the holding area (
/data/IA/uploads). These will be calledhprDDDD.typewhereDDDDis a four-digit number, andtypeis an audio type such asmp3andogg. - Any shows found this way are checked to see if they are on the IA, and if not they are queued for processing.
- Once the holding area has been scanned the queued shows are uploaded:
- Metadata is generated in the form of a CSV file by
make_metadatawith instructions for uploading the show notes and audio files. - A Bash script file is generated by
make_metadatawhich contains commands to upload non-audio files - if there are any. - The CSV is fed to the
ia uploadcommand. - The Bash script (if any) is run.
- Metadata is generated in the form of a CSV file by
- It can take a few minutes to possibly hours for the shows to be fully loaded
and accessible on
archive.org.
Check the status of an upload
Once the upload has finished as far as the various scripts (like
future_upload) are concerned the IA software takes over on the various
servers. If you have the required authorisation (being an administrator of the
HackerPublicRadio collection) then it's possible to use the web page for a
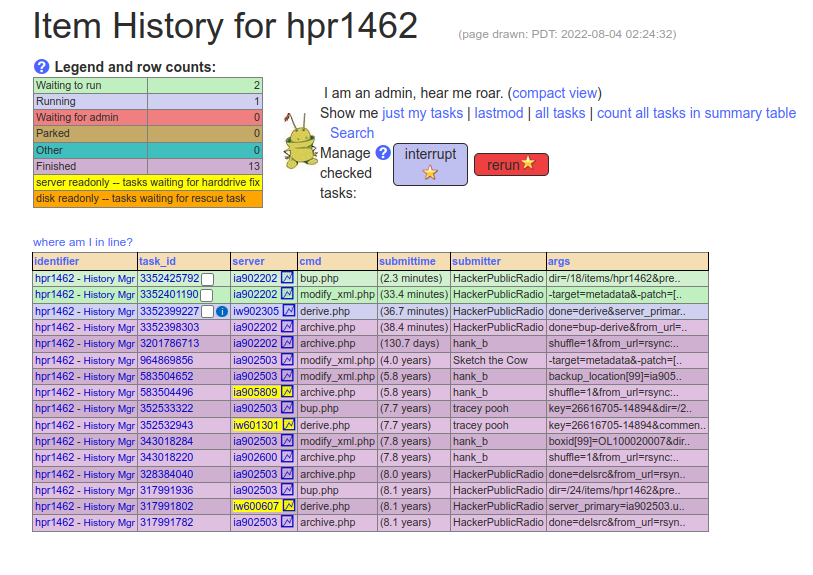
given show to determine if all the IA tasks are complete.
Here is an example of what can be seen when the History link is activated:
Refresh the show notes on the IA
If the notes in the database are changed on the HPR server it's necessary to
propagate the changes to the IA. At present this is done the hard way by
running make_metadata and then running ia.
When running make_metadata the mode chosen is just to generate the metadata
without downloading files for upload. The example below shows this being done
to correct the notes for show 3523. Note that the CSV file created is called
metadata_3523.csv.
The ia command just updates the IA metadata. It uses the bulk mode and reads
the CSV file created above, specified with --spreadsheet option.
What the warning messages returned by ia mean is unknown. These are not
always shown and the process always seems to work quite reliably.
$ ./make_metadata -from=3523 -out -meta -noassets
Output file: metadata_3523.csv
$ ia metadata --spreadsheet=metadata_3523.csv
hpr3523 - success: https://catalogd.archive.org/log/3114823140
hpr3523 - warning (400): no changes to _meta.xml
hpr3523 - warning (400): no changes to _meta.xml
hpr3523 - warning (400): no changes to _meta.xml
hpr3523 - warning (400): no changes to _meta.xml
hpr3523 - warning (400): no changes to _meta.xml
The -noassets option is important in case the item in question contains
assets - supplementary files such as photographs and examples. Without this
make_metadata will download any assets that there may be.
The -out option causes output to be written to a file where the name if
generated by the script. The -meta option means metadata only since we are
only changing metadata here.
To update multiple shows do as the following example which adds missing notes to shows 3555 and 3568 (added on 2022-04-18):
$ ./make_metadata -list=3555,3568 -out -meta -noassets
Output file: metadata_3555-3568.csv
$ metadata=metadata_3555-3568.csv
$ ia metadata --spreadsheet=$metadata
hpr3555 - success: https://catalogd.archive.org/log/3231074147
hpr3568 - success: https://catalogd.archive.org/log/3231074213
Delete a show from the IA
This occurs when a show needs to be removed from the HPR system and the IA. Examples in the past have been:
- failure to get approval from a person or organisation to release the content - perhaps delayed realisation that this is needed.
- show content that generates complaints or which might be legally dubious or outright illegal.
The process described here is not true deletion, since when an IA identifier (show in our case) has been created it cannot be deleted - except by IA Administrators, who are usually very reluctant to do it.
What is done to the IA item is that it has all files removed and all of the
metadata is either removed or replaced by Reserved.
A script has been written to assist with this called delete_ia_item which
takes the episode identifier as an argument. By default it runs in dry-run
mode where no changes are made. The script checks that the item actually
exists on the IA, then it either reports what commands it will run (in
dry-run mode) or it performs the commands.
As of 2022-05-09 the live mode does not actually perform the commands, it simply echoes them. This is because the script has not yet been fully tested in a live situation. Once that has been done the commands will be made active.
The commands issued use the ia tool described elsewhere in the Wiki. It uses
ia delete to remove all the files then calls ia metadata a number of times
to change or remove metadata fields. In some cases the removal needs to know
what values to remove, so ia metadata is used to write all of the metadata
to a temporary file and the jq tool is used to parse out the required
values.
TBA
- There is a way of hiding items on the IA, which it seems that an administrator of a collection can implement. Not clear about this but it warrants investigation.
Deal with shows that are in the wrong collection
When a show is uploaded to the IA it should be assigned to the collection
called 'hackerpublicradio'. Very rarely, it will be assigned to the default
collections: 'Community Audio' and 'Community Collections', possibly
because the metadata (which specifies the collection) is faulty or isn't read
properly. This error has been quite rare over the history of uploading shows.
It was discovered on 2022-06-15 that show 2234 was in the wrong collections. Tests were performed to see if any other shows had been wrongly assigned without being noticed.
In case it ever happens again, here are the steps which were performed:
-
All of the identifiers in the
'hackerpublicradio'collection were downloaded with the command:
ia search "collection:hackerpublicradio" -f identifier -s 'identifier asc' > hackerpublicradio_collection.json -
This generates a file with JSON objects that look like:
{"identifier": "hpr3630"}
The list also contains the batches of shows uploaded before 2014. -
An AWK script was written to find any gaps. The script is called
check_IA_identifiers.awk. See below for the script and how it was run. -
The script was run against the JSON file, which had been filtered with
jqand it showed that the only missing show was 2243.
AWK script check_IA_identifiers.awk
# check_IA_identifiers.awk, Dave Morriss, 2022-06-15
#
# Collect all 'hprxxxx' show identifiers into a hash
#
/^hpr/{
id[$1] = 1
}
#
# Post process the hash. The range is 1..3630 because that's the minimum and
# maximum show numbers as of 2022-06-15
#
END{
min = 1
max = 3630
#
# Make a x loop counting from min to max
#
for (i = min; i <= max; i++) {
#
# Make an HPR show identifier
#
show = sprintf("hpr%04d",i)
#
# If the id is not in the hash report it. Note you can't do "(show not
# in id)" or "!(show in id)", which seems an AWK shortcoming.
#
if (show in id == 0) {
printf ">> %s\n",show
}
}
}
# vim: syntax=awk:ts=8:sw=4:ai:et:tw=78:
Running the script check_IA_identifiers.awk
The way to run this is as follows:
$ awk -f check_IA_identifiers.awk < <(jq -r .identifier hackerpublicradio_collection.json | grep -E 'hpr[0-9]{4}')
>> hpr2243
The jq filter (in raw mode -r) outputs the value of the identifier key.
The grep excludes the older IA items uploaded before 2014.
The only show found was hpr2243.
Correcting the collection(s) for a show
This can only be done by the IA staff. Send an email to info@archive.org
reporting the item and explaining the issue. The item should be in the
collections 'Hacker Public Radio' and 'Podcasts'.